How to Build Scalable APIs That Grow With Your Business
In today's digital ecosystem, your API isn't just a technical project-it's a core business asset. It's the channel through which your services reach customers, partners, and internal applications. What happens when your business takes off? A poorly designed API can buckle under pressure, becoming a bottleneck that stifles growth.
Building a scalable API means designing it today to handle the success of tomorrow. It's all about creating a system that is resilient, performant, and maintainable, no matter how many users you onboard or how complex your features become. This guide will walk you through the essential principles and strategies to build APIs that scale seamlessly with your business.
1. Laying the Foundation: What does "Scalable API" really mean?
Before we dive into the "how," let's define the "what." In the context of APIs, scalability is the ability of a system to handle an increasing amount of work by adding resources to it.
But this is a manifold notion that goes beyond mere handling of more traffic:
Load Scalability: This is what most people think of—can your API serve 10, 10,000, or 10 million requests per minute without slowing down or crashing?
Complexity Scalability: Suppose your business is adding new features; can your API architecture handle them so it doesn't turn out to be some tangled, unmanageable mess?
Team Scalability: Can multiple development teams work on different parts of the API simultaneously without constantly breaking each other's code?
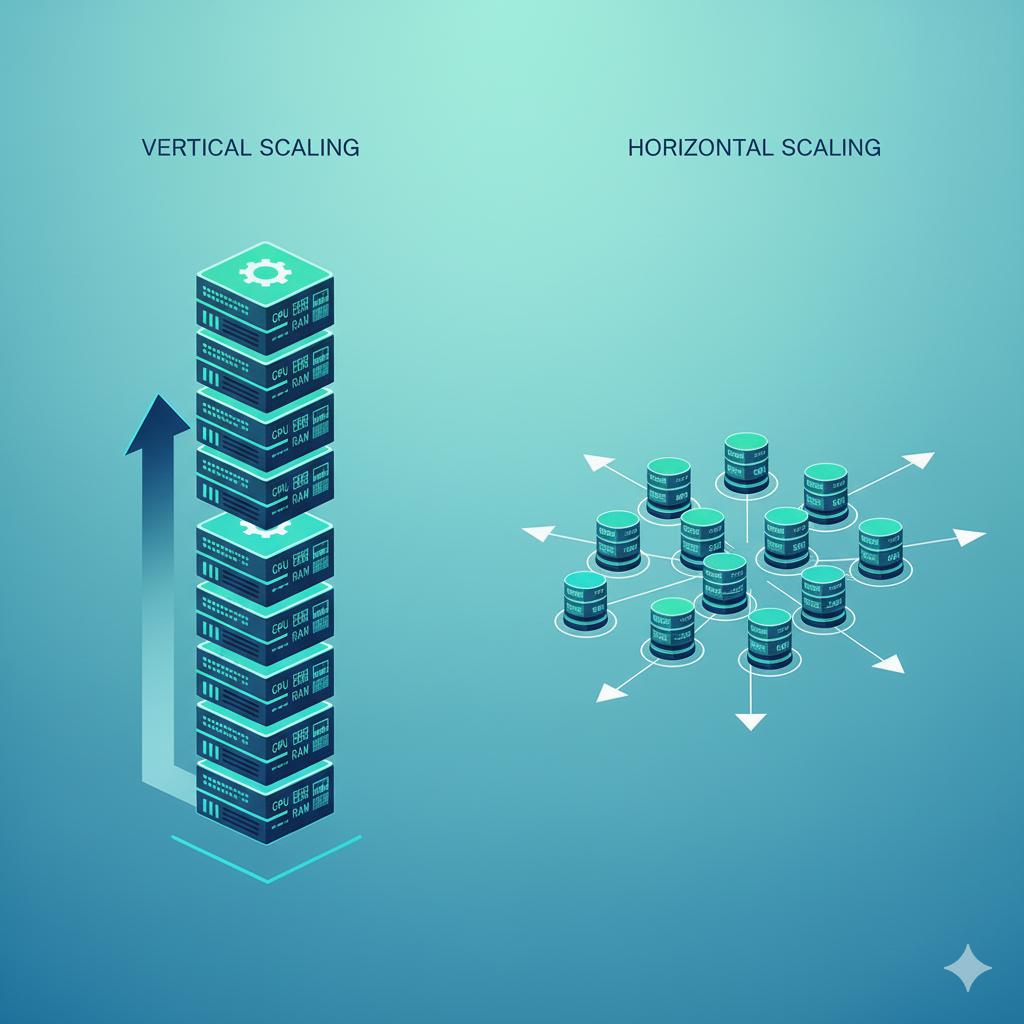
Crucially, there are two main technical approaches to scaling:
Vertical Scaling: In this, more power means adding CPU and RAM to one's existing server. It's simpler and has physical and cost limits.
Horizontal Scaling (Scaling Out): Adding more servers to your pool, spreading the load across them. This is the basis of modern, cloud-native scalability and is what we will focus on.
A truly scalable API is one designed for horizontal scaling right from day one.
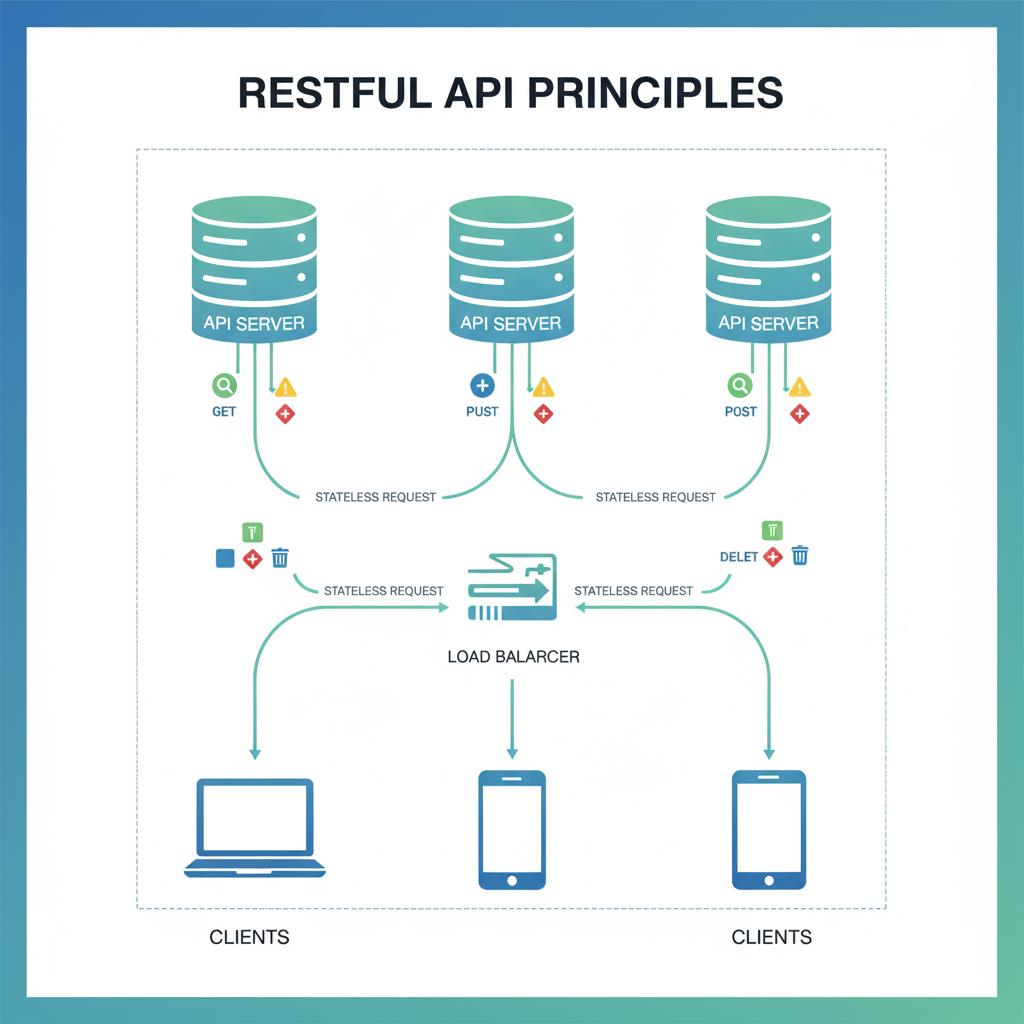
2. Design for Tomorrow: The Power of RESTful Principles & Statelessness
The best tool for ensuring long-term scalability is a clean, consistent design. REST, or Representational State Transfer, has endured to this day as a set of architectural principles that achieve just that.
Using standard HTTP methods (GET, POST, PUT, DELETE) and organizing your application into logical resources-e.g., /users, /orders-creates an API that's intuitive and predictable. It minimizes development time and reduces errors for everyone consuming your API.
The most important RESTful constraint in terms of scalability is Statelessness.
What it means: Every API request should contain all of the information the server needs to process the request. The server shouldn't maintain any session state between requests (such as user authentication tokens or session data).
Why it's crucial for scalability: In a stateless system, any server in your fleet can handle any request from any client. This is the bedrock of horizontal scaling. If one server fails, incoming requests can be instantly routed to another without any loss of context. If you need to handle more traffic, you simply add more servers behind a load balancer.
Scalable Approach: Every request carries a JSON Web Token (JWT) with user information in its Authorization header.
Not Scalable: A user's session is stored in the memory of a specific server, and all of their requests are forced to that server.
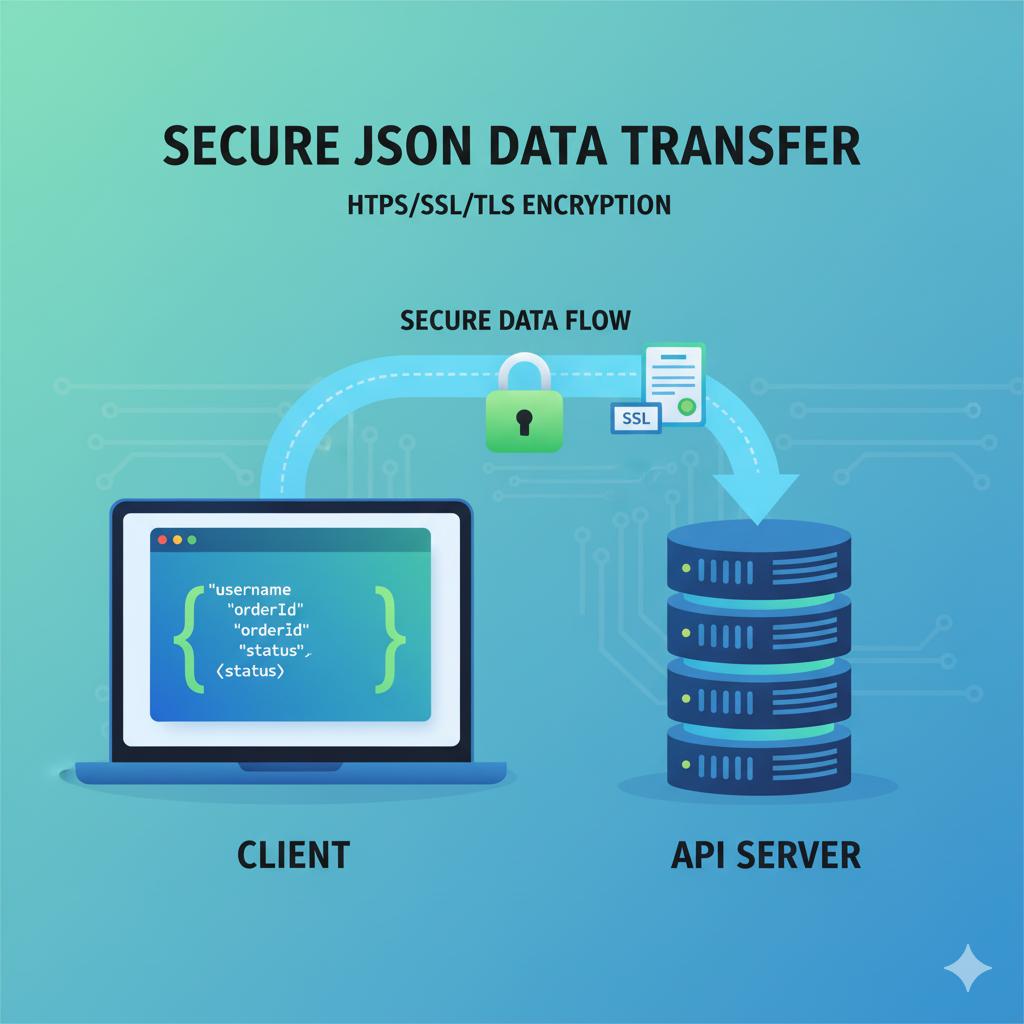
3. Speak a Universal Language: The JSON & HTTPS Standard
Scalability is not just about servers, but about the developer ecosystem and security, too. Using universal standards cuts friction and builds trust.
JSON is the undisputed champion when it comes to exchanging data through APIs. It's lightweight, human-readable, and has native support across just about every programming language. By using JSON, you ensure that the developers building on your platform can parse and create data efficiently, which speeds up the process of integration and innovation.
HTTPS is a must-use, non-negotiable. It offers three very crucial advantages:
Encryption: Protects data in transit between the client and your server.
Data Integrity: Prevents data from being tampered with during transfer.
Authentication: Ensures your users are talking to your legitimate API server and not an imposter.
From an SEO and user trust perspective, HTTPS is a ranking signal for Google and is required for many modern web features. Building your API on HTTPS from the start future-proofs it against security and compliance requirements.
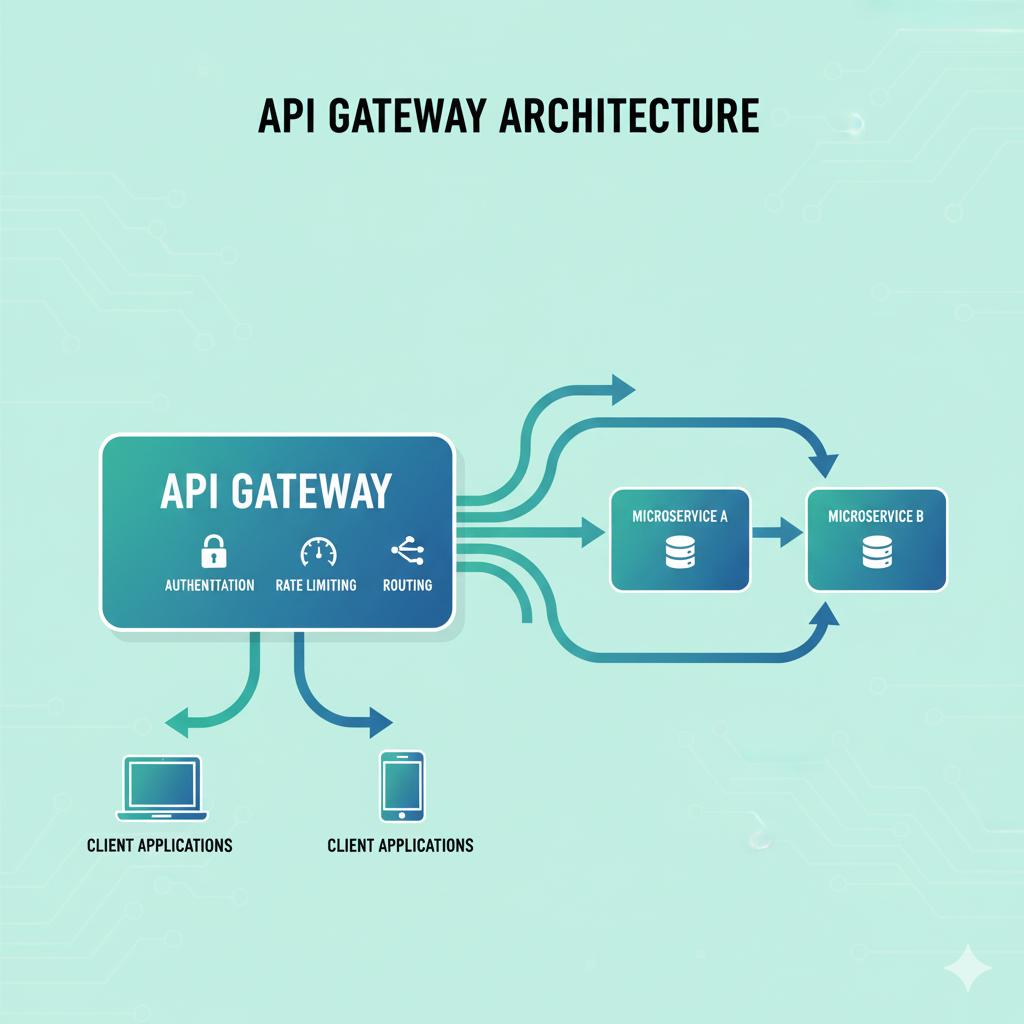
4. Don't Reinvent the Wheel - Leverage API Gateways
As an API grows, tasks such as authentication, rate limiting, and routing requests become complex. Directly embedding this logic into your API code creates a maintenance nightmare and violates the single-responsibility principle.
The solution is API Gateway.
An API Gateway serves as an entry point for all API requests. It's a dedicated layer that handles "cross-cutting concerns" even before the request reaches your core business logic.
Key benefits for scalability:
Offloads Common Tasks: The gateway handles authentication, SSL termination, IP whitelisting, and logging, so your microservices can focus purely on business logic.
Intelligent Routing: It can route requests to the appropriate backend service-for example, /users to the User Service or /orders to the Order Service. This is the traffic cop for your microservices architecture.
Aggregates Responses: This can fetch data from multiple microservices and create one unified response for the client, thus reducing the number of round trips.
Offers Rate Limiting: It can be used to enforce usage quotas per API key, which protects your backend services from being overwhelmed.
This is what tools such as Kong, AWS API Gateway, or Azure API Management give you right out of the box, not having to build this complex infrastructure yourself.
5. Cache Smartly: Boost Performance and Reduce Server Load
One of the most effective ways to scale is to not do work that isn't necessary. Caching temporarily stores copies of frequently accessed data in fast storage rather than recomputing it or fetching from a slow database each time.
A multi-layered caching model is fundamental:
Client-Side Caching: Implementing HTTP headers such as Cache-Control and ETag will enable browsers and client applications to cache responses locally. This is the fastest possible cache.
API Gateway / CDN Caching: Cache full API responses at your gateway or a Content Delivery Network (CDN) for read-heavy, static, or semistatic data, such as product catalogs and user profiles.
Application Caching: Employ an in-memory data store, like Redis or Memcached, to cache the results of expensive database queries or computed values. Example: caching a user's shopping cart or a complex report.
By applying caching strategically, you get to greatly reduce latency for end-users while drastically reducing the load on backend databases, which tends to be the most challenging part of any system to scale.
6. Break Down the Monolith: An Introduction to Microservices
At first, it might be simple to develop and deploy a monolithic architecture—where all your application logic is bundled together into a single, unified unit. But as your business and codebase grow, that turns into a major blocker for scalability.
A monolith is hard to scale because you need to scale the whole application, even though only one feature might have a high load. It becomes a development bottleneck, too, since large teams are forced into working with a big, entangled codebase.
A Microservices Architecture is the solution.
This approach structures an application as a collection of loosely coupled, independently deployable services. Each microservice is a mini-application in itself that owns its data and has responsibility for some specific business domain, such as User Service, Payment Service, Notification Service.
Why microservices enable massive scalability:
Independent Scaling: You can scale only those services that require scaling. If you have a spike in video processing, you can add more resources to just your "Video Service" without touching the "User Service."
Focused Development: Small, autonomous teams can develop, deploy, and scale their services much faster.
Technology Diversity: Each service can utilize a technology stack - programming language, database - that best fits the job at hand.
While microservices bring in additional complexity in communication and orchestration, they are the architectural pattern that empowers the world's largest tech companies to scale globally.
7. Know Your Data: Choosing the Right Database & Using Indexes
The database usually serves as a point of limitation in many applications. Throwing more servers at your API is futile if the database underneath is struggling to keep up. There are two key decisions when it comes to a scalable data strategy: choosing the right tool for the job and using it efficiently.
Embrace Polyglot Persistence
Gone are the days of the one-size-fits-all database. Polyglot persistence means using different data storage technologies to fit different data needs. Your choice should be driven by how you access and use the data:
Relational Database Systems SQL: Suited for structured data when complex queries, transactions, and data integrity are essential-PostgreSQL and MySQL. Use them for user accounts, financial records, or anything that relies heavily on the relationships between different pieces of data.
NoSQL/document databases-MongoDB and Couchbase are perfect for semi-structured or hierarchical data, such as product catalogs, user profiles, or content. The flexible schema allows fast iteration in those cases.
In-Memory Databases: Redis, Memcached. Used for caching, storing sessions, and leaderboards in real time. They offer blistering speeds by keeping data in RAM.
Time-Series Databases (InfluxDB, TimescaleDB): Optimized for handling sequences of data points in time, such as IoT sensor data, application metrics, or financial tickers.
The Unsung Hero: Database Indexing
Regardless of which database you use, indexes are how you'll keep performance tuned as you grow. An index is like the alphabetical index at the back of a book. Rather than scanning every single row—a "full table scan"—the database uses the index to find data.
Without an index, finding a user based on email would have to involve the database checking every user record.
With an index on email: The database can immediately jump to the correct record.
Proper indexing is key to performance, but keep in mind that indexes have a write penalty because they have to be updated upon INSERT/UPDATE, so apply them judiciously on columns being commonly queried.
8. Handle the Rush: Rate Limiting and Throttling
A scalable API must be a good citizen and protect itself. Rate limiting is the practice of controlling the amount of traffic a single user or API key can send to your API within a given time window, like 1,000 requests per hour.
This isn't just about preventing malicious DDoS attacks. It's essential for:
Fair Usage: A given consumer cannot dominate the use of your API and impact the experience of others.
Cost Control: Prevent unexpected traffic spikes from skyrocketing the cloud infrastructure bills.
Service protection will protect your backend services and databases from being overwhelmed by buggy client code or runaway processes.
Common rate limiting strategies include:
User-based: Limits are applied per API key or authenticated user.
IP-based: A fallback for limiting unauthenticated traffic.
Tiered plans allow you to offer different limits (e.g., Free, Pro, Enterprise) in your API product.
As discussed in Part 1, the API Gateway is the ideal location to handle this logic across all your services consistently.
9. The Art of Pagination, Filtering, and Searching
Never return the whole database as a single response from the API. It's a performance killer for your servers, a bandwidth hog for your clients, and a terrible user experience. Instead, provide tools to clients for efficiently finding the data they need.
Pagination breaks down large result sets into manageable chunks, called pages.
Offset-based Pagination (limit & offset): GET /articles?limit=20&offset=40 (Give me 20 articles, skipping the first 40). It is easy to implement but inefficient on large datasets.
Cursor-based Pagination: GET /articles?limit=20&cursor=abc123 (Give me 20 articles after the one with ID 'abc123'). More performant and stable for large real-time datasets since it's not affected by new entries shifting the offset.
Filtering and searching enable users to filter down results.
Filtering: The query parameters should be used for exact matches on specific fields. GET /products?category=electronics&price_range=100-500
Searching: Provide a specialized search endpoint GET /products?q=laptop that will allow performing a fuzzy full-text search across multiple fields.
By providing these features, the burden of data slicing shifts away from your server and onto the client. This makes your API more efficient and flexible.
10. Stay Informed: The Role of Comprehensive Logging and Monitoring
You can't fix or scale what you can't see. In a distributed system of many microservices, making guesses where a problem happened is a surefire recipe for long downtimes and frustrated teams.
The Three Pillars of Observability:
Logging: Each service should output structured logs (e.g., in JSON format) for each significant event and especially errors. Collect them within something like an ELK Stack (Elasticsearch, Logstash, Kibana) or Loki so that you can track what happened to a request through all of your architecture.
Metrics: Gather numeric data regarding the behavior of your system.
Application Metrics: Request per second, error rates (4XX, 5XX), and latency - avg., 95, and 99th percentile.
System metrics include CPU, memory, and disk I/O of your servers.
Business Metrics: New sign-ups, orders placed etc.
Tools such as Prometheus for collecting and Grafana for visualization are considered an industry standard here.
Alerting: Define intelligent alerts based on your metrics. Instead of alerting on "server is down", alert on "error rate is above 1%" or "p95 latency has exceeded 500ms for 5 minutes." This will enable you to be proactive rather than reactive.
11. Prepare for the Worst: Building Resilience with Circuit Breakers
In a microservices architecture, your API's stability often depends upon the health of other services. If the "Payment Service" is slow or down, what happens to your "Checkout Service"? This would result in the Checkout Service continuing to wait for a response, eventually running out of its resources (such as database connections or threads), and crashing. This is what one might call a cascading failure. The Circuit Breaker pattern is your solution. It works exactly like an electrical circuit breaker: Closed State: Requests flow normally to the dependent service. The circuit breaker monitors for failures. Open State: If the failure rate exceeds a threshold, the circuit "trips" into the Open State. All requests to the failing service are failed immediately for a predetermined period without making the call. This allows the failing service time to recover and avoids resource exhaustion in the calling service. Half-Open State: The circuit switches to a Half-Open state after the timeout, which allows a test request to pass. If successful, the circuit closes again; if not, it goes back to Open. So, by using libraries such as Resilience4j for Java or Hystrix, which is a bit old-fashioned but defines this concept itself, you will find that the implementation is straightforward. This will allow your whole system to be fault-tolerant.
12. Future-Proof with Versioning: How to Evolve Your API Without Breaking It
Change is inevitable. Your business will require new features and existing endpoints will need improvements. However, breaking changes like renaming a field or removing an endpoint will infuriate your developers and erode trust.
The solution is an explicit API Versioning Strategy. Your objective is to evolve the API while keeping compatibility with existing consumers. Common Versioning Strategies: URL Path Versioning (/api/v1/users, /api/v2/users): This is the most straightforward and transparent method. Everyone can see the version in the request. It is highly cacheable, and is the most common approach. Query Parameter Versioning (/api/users?version=2): like path versioning, but not as explicit.
Useful for doing gradual rollouts. Custom request header (Accept: application/vnd.myapi.v2+json): This keeps URLs clean and is considered more "RESTful." However, it's less discoverable and can be harder to debug and cache. Conclusion: Scalability is a Journey, Not a Destination Building API scalability is not something you check off a list but rather commit to through continuous thoughtful design, proactive monitoring, and strategic iteration. By internalizing the principles we have covered across these twelve headings-from the foundational statelessness and RESTful design to the advanced patterns of circuit breakers and microservices-you are not just building a product.

Aug 10, 2025

Aug 24, 2023

Aug 24, 2023

Aug 24, 2023

Aug 24, 2023